新加坡和中国的一个联合团队近日公布了最新的AI研究技术,可以通过输入文本直接生成相应的3D虚拟图像,引起业界热议。让我们来看看。

【/h/】目前各种3D虚拟影像基本都要求制作者具备丰富专业的影像处理技术,普通人很难达到。但是,来自新加坡南洋理工大学、中国SenseTime Research和上海ai实验室《的新技术。头像剪辑:零镜头文本驱动的3D头像的生成和动画》从根本上改变了这种情况,让没有任何专业知识的人也能轻松创作出各种3D虚拟形象。
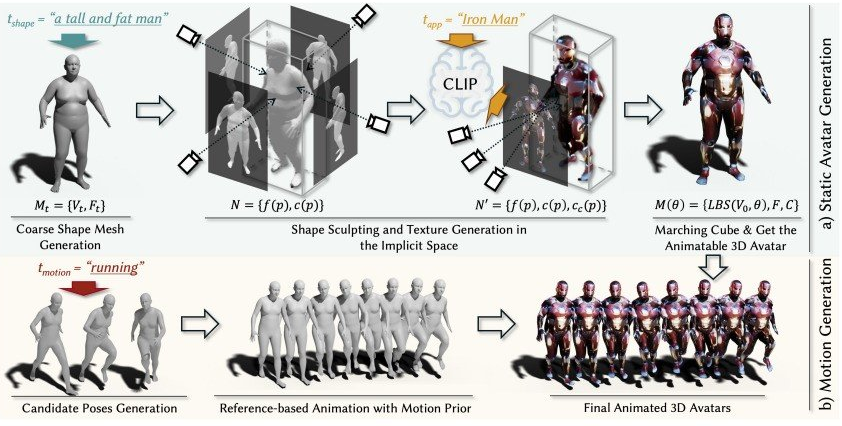
比如文字“我要生成一个正在奔跑的又高又胖的钢铁侠。”意思是做一个奔跑的胖铁人。或者“我想生成一个正在举臂的瘦子忍者”,生成一个更瘦的举臂忍者等等,直接通过文字生成对应的3D虚拟形象,当然如果你的描述更详细,会更接近你想要的目标形象。